一、“苦涩教训”到底在说什么?(核心观点通俗版)
强化学习之父 Rich Sutton 在 2019 年写下的《The Bitter Lesson》,撕开了 AI 发展的一个反直觉真相:
“短期靠人类知识‘喂’机器能快速见效,但长期来看,砸算力 + 用通用方法(比如搜索、学习)的‘笨办法’,才是真正的赢家。”
这教训“苦涩”在哪?
就像你费尽心机教 AI 下围棋(比如写死“金角银边”规则),短期内 AI 能赢新手,特有成就感。但等算力上来后,AlphaGo 用“自我对弈 + 搜索”的通用方法,直接碾压你的“知识注入型”AI——之前的心血全成了无用功。
根本原因很现实:算力成本每年都在暴跌(摩尔定律持续生效)。你还在纠结“怎么教机器”时,别人已经靠堆算力让通用方法跑通了,而且越跑越强。
二、历史反复验证:四个领域的“打脸时刻”
AI 七十多年的发展,其实就是“人类知识注入”被反复打脸的历史。这四个关键节点尤其典型:
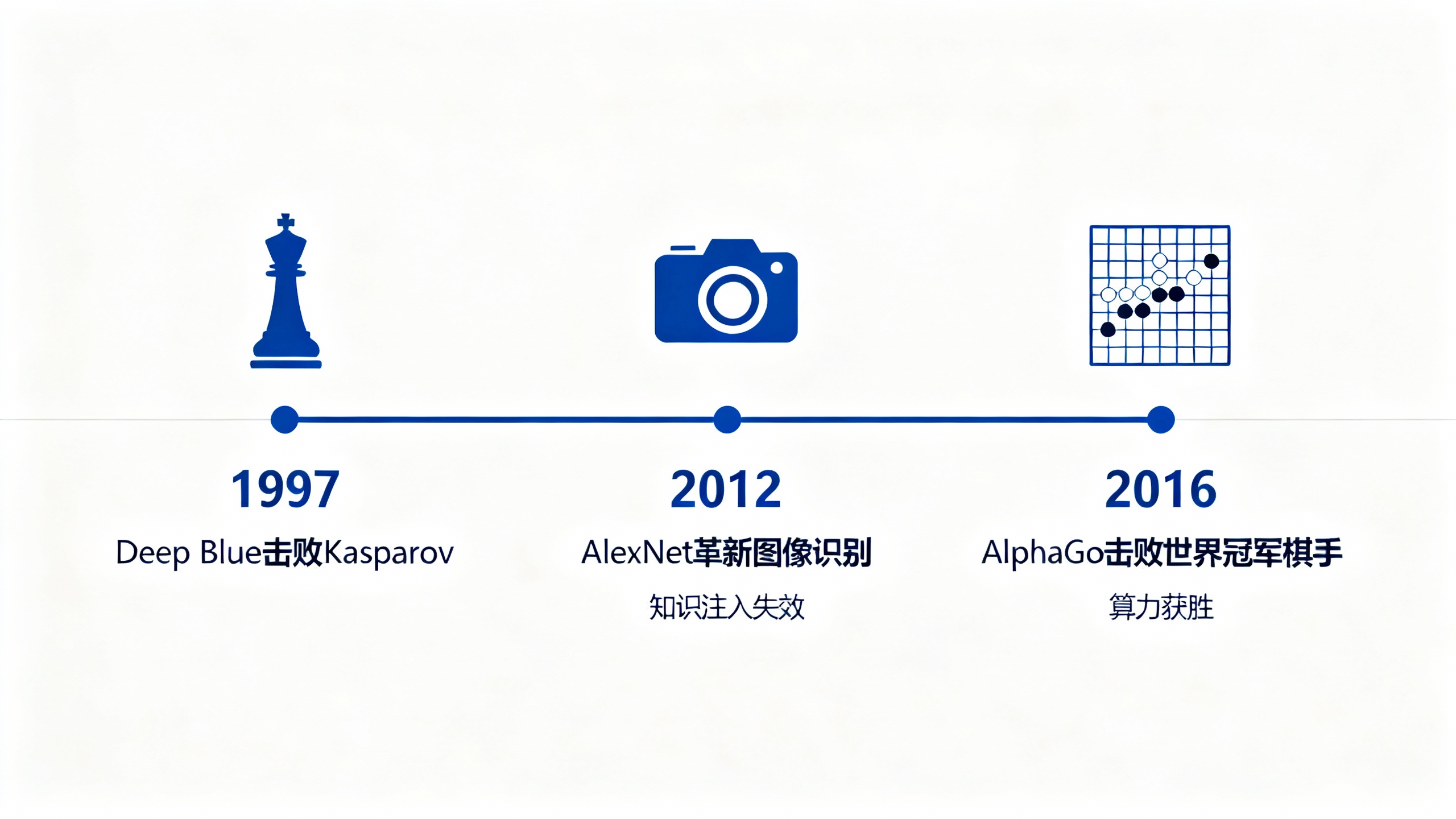
- 国际象棋(1997 年):IBM 深蓝靠暴力搜索赢卡斯帕罗夫,那些沉迷“复刻人类棋谱”的研究者傻眼了;
- 围棋(2016 年):AlphaGo 用“深度学习 + 蒙特卡洛搜索”吊打李世石,此前 20 年“靠围棋规则设计 AI”的努力全白费;
- 语音识别(1970 年代):DARPA 竞赛中,“统计模型 + 多计算”干翻了“靠声道知识设计的系统”,CMU 的 HEARSAYⅡ 系统虽靠语言学知识实现 97% 准确率,但后续仍被统计模型超越;
- 计算机视觉(2012 年):AlexNet 出现前,研究者靠人工找“边缘特征”,而 CNN(卷积神经网络)只用通用算法,效果直接甩十条街。
Sutton 总结的规律堪称真理:
人类知识注入→短期进步→遇瓶颈→被“算力 + 通用方法”秒杀
三、2025 年最新印证:AI 大佬们还在聊这个
今年以来的大模型动态,再次印证了“苦涩教训”的正确性:
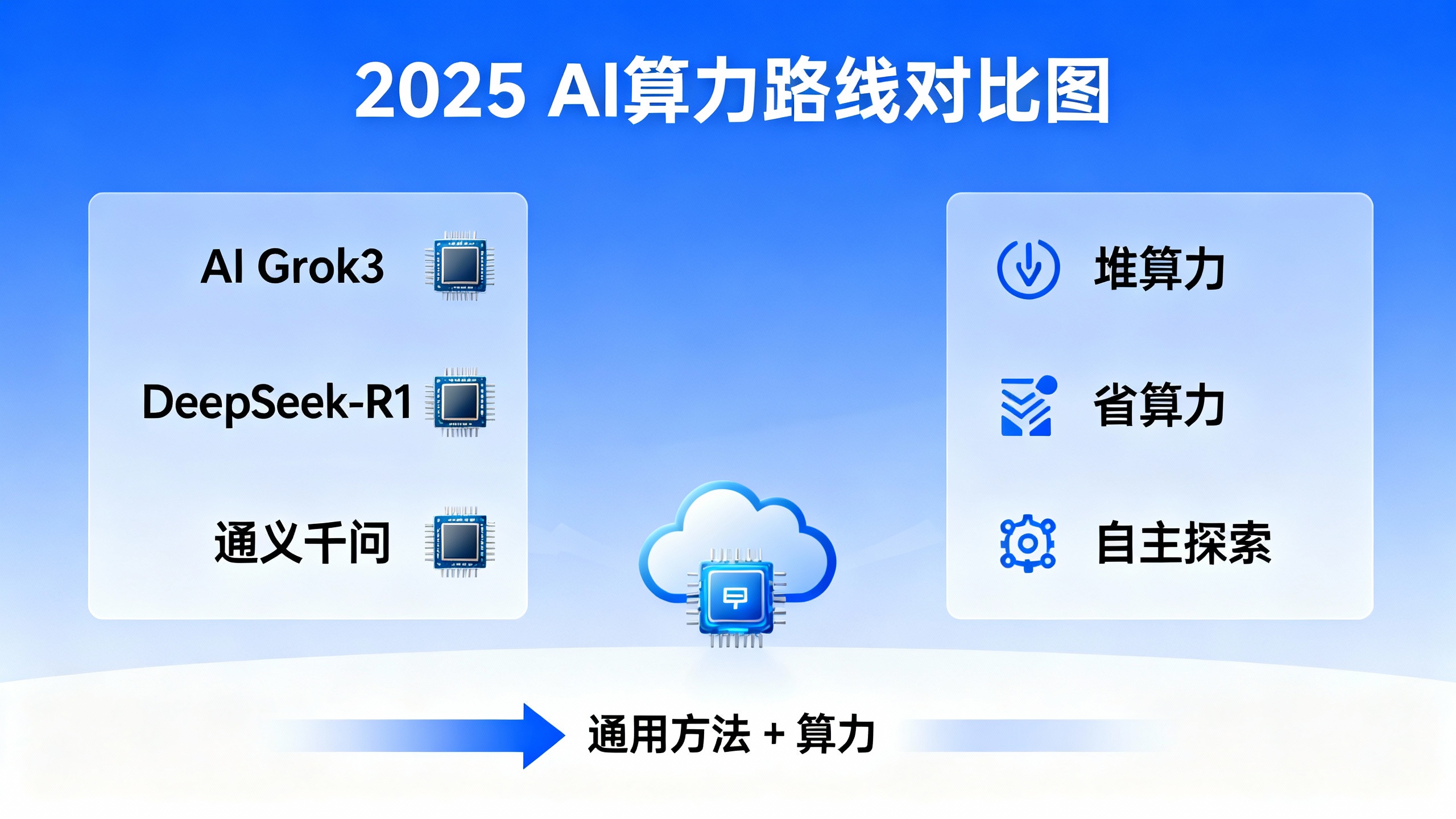
- 前 OpenAI 首席科学家 Ilya 说“预训练到头了”,但 Transformer 共同发明者 Noam 立刻补刀:“提升实时算力(Test-Time Compute)才是关键”,他在 HotChips2025 大会上直言“算力越多越好”;
- 马斯克的 Grok3“堆算力硬冲”参数纪录,DeepSeek-R1 则“优化工程省算力”,看似路线不同,本质都是“靠通用方法挖算力潜力”;
- 通义千问开源智能体时直言:“不写死规则,让模型自己推理探索”——这正是“苦涩教训”的现实验证。
现在行业里没人再纠结“怎么把人类知识灌进模型”,而是比拼“如何让通用模型更高效地利用算力”。
四、个人怎么应对?三个“反焦虑”行动指南
作为技术人,与其焦虑被 AI 替代,不如主动拥抱这种逻辑。结合我的实践经验,分享三个可落地的方向:
1. 思维先转:别当“知识的搬运工”
- 放弃“全知幻觉”:别总想着“把所有知识学会再行动”。就像 AI 不用背完棋谱才赢,我学 Python 时也没看完教材,直接用 GPT 辅助写脚本,边错边改反而学得更快;
- 抓“元能力”而非“知识点”:比如学 Excel,别死记函数参数(知识点),要学“怎么用搜索 / 插件解决新问题”(元能力)——这对应 AI 的“通用方法”。
2. 能力聚焦:练“能借算力放大的本事”
根据 Sutton 强调的“搜索 + 学习”两大通用技术,个人重点提升这三项能力:
- 工具使用力:熟练用 AI 工具(Copilot 写代码、ChatGPT 查资料)、云算力平台(腾讯云、AWS)——相当于给大脑装“外接算力”;
- 持续学习力:用“最小行动 + 快速迭代”代替“完美准备”,这和 AI 的“自我对弈学习”逻辑一致;
- 工程化思维:做事情留“可扩展接口”,比如我写报告必用模板,下次能直接套新数据——就像 AI 模型能接更多训练数据。
3. 避坑提醒:知识不是没用,别当“天花板”
“苦涩教训”不是否定知识,而是别让知识限制你:
- 用知识“搭梯子”而非“筑围墙”:我做 AI 应用时,懂基础算法能快速入门,但真正出效果靠的是“数据测试(搜索)+ 用户反馈(学习)”优化;
- 稀缺领域抓知识:医疗、法律等数据少的领域,人类经验仍很重要。比如学医,基础解剖知识必须扎实,但也要用 AI 辅助看 CT 片(知识 + 算力结合)。